
티스토리 뷰
k-최근접 이웃(k Nearest Neighbors, kNN)알고리즘은 데이터 분류에 사용되는 간단한 지도학습 알고리즘 이에요.
이 알고리즘은 현재 데이터를 특정값으로 분류하기 위해 기존의 데이터 안에서 현재 데이터로부터 가까운
k개의 데이터를 찾아 k개의 레이블 중 가장 많이 분류된 값으로 현재의 데이터를 분류합니다!
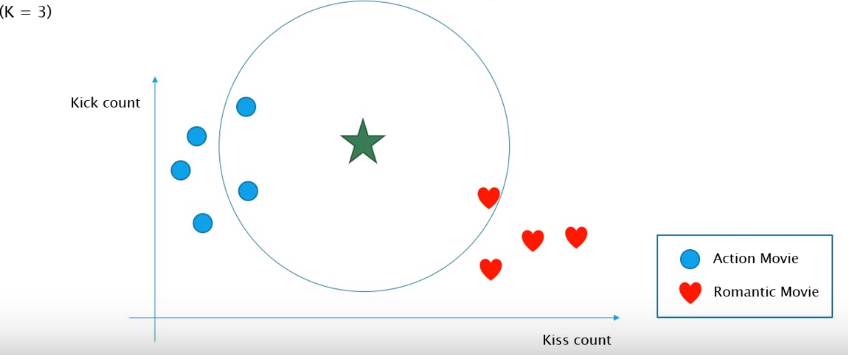
위의 그림을 kNN알고리즘 관점으로 본다면 ★이라는 테스트 데이터는 좌표상에서 자기 위치로부터 가까운
3개의 기존 데이터들(●,♥)을 찾아 과반수의 레이블(●)로 자신을 분류했습니다.
k는 짝수로 지정할 경우, 2n:2n의 상황이 발생해 분류하기 애매해 질 수 있으므로, k는 홀수로 지정해주는게 관습입니다!
장점
- kNN 알고리즘은 다른 머신러닝 알고리즘보다 이해하기가 상당히 쉽습니다.
다른 알고리즘은 미적분, 확률 및 정보 이론 등의 기본 지식이 필요한 데 비해 kNN알고리즘은 수학적으로 거리를 계산하는 방법만 알면 이해하기가 쉽습니다.
- 숫자로 구분된 속성에 우수한 성능을 보입니다.
거리, 횟수, 점수와 같이 수치화된 데이터에 대해서는 거리 기반 머신러닝 알고리즘인 kNN 알고리즘을 사용하면 높은 정확도를 기대할 수 있습니다.
- 별도의 모델 학습이 필요 없습니다.
kNN 알고리즘은 예측을 하는 시점에서 모든 기존 데이터와의 거리를 계산하기 때문에 예측 전에 모델을 따로 학습시킬 필요가 없습니다.
단점
- 예측 속도가 느립니다.
하나의 데이터를 예측할 때마다 전체 데이터와의 거리를 계산하기 때문에 연산 속도가 다른 알고리즘에 비해 느립니다.
- 예측값이 지역 정보에 편향될 수 있습니다.
kNN알고리즘은 오직 가까운 이웃을 통해 예측하기 때문에 k의 개수가 적거나 몇 개의 예외적인 데이터가 이웃으로
존재할 경우 예측값이 틀릴 가능성이 있습니다.
<참고 문헌 / 이미지 출처>
-https://www.youtube.com/watch?v=CyuI2F_wJWw&list=PLVNY1HnUlO241gILgQloWAs0xrrkqQfKe&index=3
-Minseok-Heo, [나의 첫 머신러닝/딥러닝], Wikibooks, 2019.
이 글은 저자님과 출판사의 참고 허가를 받고 작성되었습니다.
'Data Science > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 선형 회귀와 경사하강법 (0) | 2019.04.14 |
|---|---|
| [Machine Learning] 서포트 벡터 머신 - SVM (0) | 2019.04.03 |
| [Machine Learning] 혼동행렬 (0) | 2019.03.29 |
| [Machine Learning] 과대적합과 과소적합 (0) | 2019.03.28 |
| [Machine Learning] 지도학습과 비지도학습 (0) | 2019.03.27 |